Cleaning Up Corporate ERP Data
The previous posts have used Excel and Python to create and manipulate small spreadsheets. In reality, Python and Excel are especially well suited to tackling large data sets. This post will illustrate some techniques for cleaning up data downloaded from corporate Enterprise Resource Planning (ERP) systems, such as SAP and Oracle, and getting it ready for some serious data mining with Excel.
In this example, a fictional company called ABCD Catering has sales and order history for 2009 in their corporate ERP system. ABCD Catering provides catering services to leading Silicon Valley companies, providing the best in hamburgers, hot dogs, sushi, bibimbap, samosas, churros, sodas, and other tasty food. Your boss has asked you to examine this data and answer some questions and produce charts representing some of the data:
- What were the total sales in each of the last four quarters?
- What are the sales for each food item in each quarter?
- Who were the top 10 customers for ABCD catering in Q1?
- Who was the highest producing sales rep for the year?
- What food item had the highest unit sales in Q4?
You typically run five separate reports in your ERP system to generate this data. Since your boss is looking for this same information at the end of each quarter, you want to simplify your life by automating the final report. Using Python and Excel, you can download a spreadsheet copy of the raw data, process it, generate the key figures and charts, and save the new data for later analysis.
Take a look at the data in ABCDCatering.xls (this data is available for download at https://github.com/pythonexcels/examples/raw/master/ABCDCatering.xls):
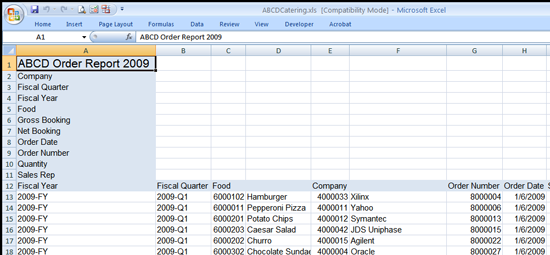
The spreadsheet contains some header information, then a large table of records for each order. Each record contains the fiscal year and quarter, food item, company id, company name, order data, sales representative, booking quantity, and order quantity for each order. Note that this data needs some modification before you can use it in a pivot table.
- The data in rows 1 through 11 must be ignored, it’s meaningless for the pivot table.
- Some columns do not have a proper header and must be corrected before the data can be used.
After performing these modifications, this data will be ideally suited for processing with a pivot table in Excel.
The program begins with the standard boilerplate: import the win32 module and start Excel. If you have questions on this, please refer to Basic Excel Driving and Python Excel Mini Cookbook.
#
# erpdata.py: Load raw EPR data and clean up header info
#
import win32com.client as win32
import sys
excel = win32.gencache.EnsureDispatch('Excel.Application')
excel.Visible = True
Next, open the ABCDCatering.xls spreadsheet with some exception
handling. The try/except clause attempts to open the file with the
Workbooks.Open() method, and exits gracefully if the file is
missing or some other problem occurred. Lastly, the variable ws is
set to the spreadsheet containing the data.
try:
wb = excel.Workbooks.Open('ABCDCatering.xls')
except:
print "Failed to open spreadsheet ABCDCatering.xls"
sys.exit(1)
ws = wb.Sheets('Sheet1')
After opening the spreadsheet, the script must read the data. An easy
way to load the entire spreadsheet into Python is the UsedRange
method. The following command retrieves the data in the Sheet1
worksheet and copies it into a tuple named xldata.
xldata = ws.UsedRange.Value
Once inside Python, the data can be manipulated and placed back into the spreadsheet with very few calls to the COM interface, resulting in faster, more efficient processing.
To delete rows, add columns and do other operations on the data, it must be converted to or copied to a list. The approach used here is to examine the data row by row, discard the nonessential header rows, and copy the remaining data to a new list. If you are using Python to generate the program interactively, you can investigate the data in the xldata tuple and display the data for the first record (xldata[0]) and header record (xldata[11]) as follows:

The length of both rows is 13, though xldata[0] contains many elements with a value of None. The following code checks the length of the data and skips any rows shorter than 13 fields or rows that contain None in the last field. Note that this code assumes that the actual data in the table always contains complete records; note that you should always understand the characteristics of your data.
newdata = []
for row in xldata:
if row[-1] is not None and len(row) == 13:
newdata.append(row)
The newdata list now contains the header and data rows from the spreadsheet, but the header row is still not complete. All column headers must contain text in order to use this data in a pivot table. Unfortunately, the spreadsheet downloads produced by the ERP system have the column label over the numerical identifier for the item, while the text column header is blank. You can see that for the “Food” and “Company” data below.
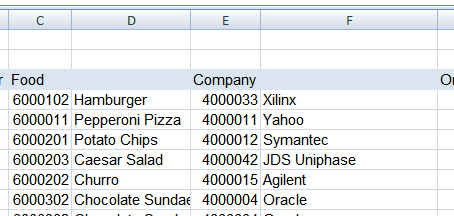
One approach that works for this data is to scan the header and insert a column header based on the contents of the previous column. For example, the label for column F could be “Company Name”, created by simply appending the text “ Name” to the column header “Company” from the previous column. Using this simple algorithm, the column header row can be completed to prepare the spreadsheet for pivot table conversion. A more complex lookup could be used as well, but the simple algorithm described here will scale if new fields are added to the report.
for i,field in enumerate(newdata[0]):
if field is None:
newdata[0][i] = lasthdr + " Name"
else:
lasthdr = newdata[0][i]
Now the data is ready to insert into the spreadsheet. To better compare the original data set and the new data set, create a new sheet in the workbook, write the data to the new sheet, and autofit the columns.
wsnew = wb.Sheets.Add()
wsnew.Range(wsnew.Cells(1, 1), wsnew.Cells(len(newdata), len(newdata[0]))).Value = newdata
wsnew.Columns.AutoFit()
The last step is to save the worksheet to a new file and quit Excel.
wb.SaveAs('newABCDCatering.xlsx', win32.constants.xlOpenXMLWorkbook)
excel.Application.Quit()
If the file newABCDCatering.xlsx already exists in My Documents or Documents, you will see the following dialog box when you run the script.
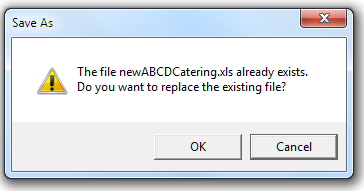
Click “Yes” to overwrite the spreadsheet file. To run the script cleanly, erase the newABCDCatering.xlsx file and try the script again.
After running the script, open the file newABCDCatering.xlsx or newABCDCatering.xls and view the contents. Note that the 11 lines of extra header information has been removed and the blank column headers have been inserted based on the contents of the previous column.
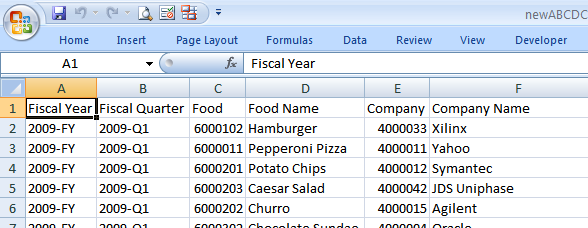
The new spreadsheet is ready for use in a pivot table, which will be covered in the next post. Here is the complete script, also available at https://github.com/pythonexcels/examples/blob/master/erpdata.py
#
# erpdata.py: Load raw EPR data and clean up header info
#
import win32com.client as win32
import sys
excel = win32.gencache.EnsureDispatch('Excel.Application')
# excel.Visible = True
try:
wb = excel.Workbooks.Open('ABCDCatering.xls')
except:
print("Failed to open spreadsheet ABCDCatering.xls")
sys.exit(1)
ws = wb.Sheets('Sheet1')
xldata = ws.UsedRange.Value
newdata = []
for row in xldata:
if len(row) == 13 and row[-1] is not None:
newdata.append(list(row))
lasthdr = "Col A"
for i, field in enumerate(newdata[0]):
if field is None:
newdata[0][i] = lasthdr + " Name"
else:
lasthdr = newdata[0][i]
wsnew = wb.Sheets.Add()
wsnew.Range(wsnew.Cells(1, 1), wsnew.Cells(len(newdata), len(newdata[0]))).Value = newdata
wsnew.Columns.AutoFit()
wb.SaveAs('newABCDCatering.xlsx', win32.constants.xlOpenXMLWorkbook)
excel.Application.Quit()
Prerequisites
Python (refer to http://www.python.org)
pywin32 Python module (refer to https://pypi.org/project/pywin32)
Microsoft Excel (refer to http://office.microsoft.com/excel)
Source Files and Scripts
Source for the program erpdata.py and spreadsheet file ABCDCatering.xls are available at http://github.com/pythonexcels/examples
Originally posted on November 2, 2009 / Updated November 1, 2022